
Conversational Image Generation: Towards Multi-Round Personalized Generation with Multi-Modal Language Models
Published in The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026
This paper addresses two main goals: (1) enabling personalization in existing multimodal large language models (MLLMs), and (2) demonstrating their ability to reason over joint text–image chat histories in non-Markov, multi-round conversations.
For personalization, we analyze SEED-X and observe that it behaves largely as a text-to-image model, producing similar faces regardless of the provided identity conditions. We identify a key bottleneck in its detokenizer, which fails to preserve fine-grained facial identity. To resolve this while maintaining good generalization, we replace the SDXL detokenizer with a personalization-enhanced DiT and introduce a multi-stage instruction fine-tuning strategy that balances identity preservation with prompt editability. Qualitative results show that our improved MLLM better integrates both facial conditions and textual instructions, rather than overemphasizing text alone.

Beyond single-round personalization, we then work on conversational, multi-round text–image interaction. Existing multi-turn image datasets (e.g., MagicBrush, SEED-Data-Edit) follow a Markov property, where each step depends only on the previous output. This dataset structure reduces multi-round generation to repeated single rounds \(\left\{p(X_a^i \vert X_t^i,X_a^{i-1})\right\}_{i=1}^N\). We instead propose a non-Markov setting that requires reasoning over the entire chat history across both text and images, \(p(X_a^i \vert X_t^i,X_v^i,\left\{X_t^k,X_v^k,X_a^k\right\}_{k=1}^{i-1})\). To this end, we introduce a name-based multi-round personalization dataset.
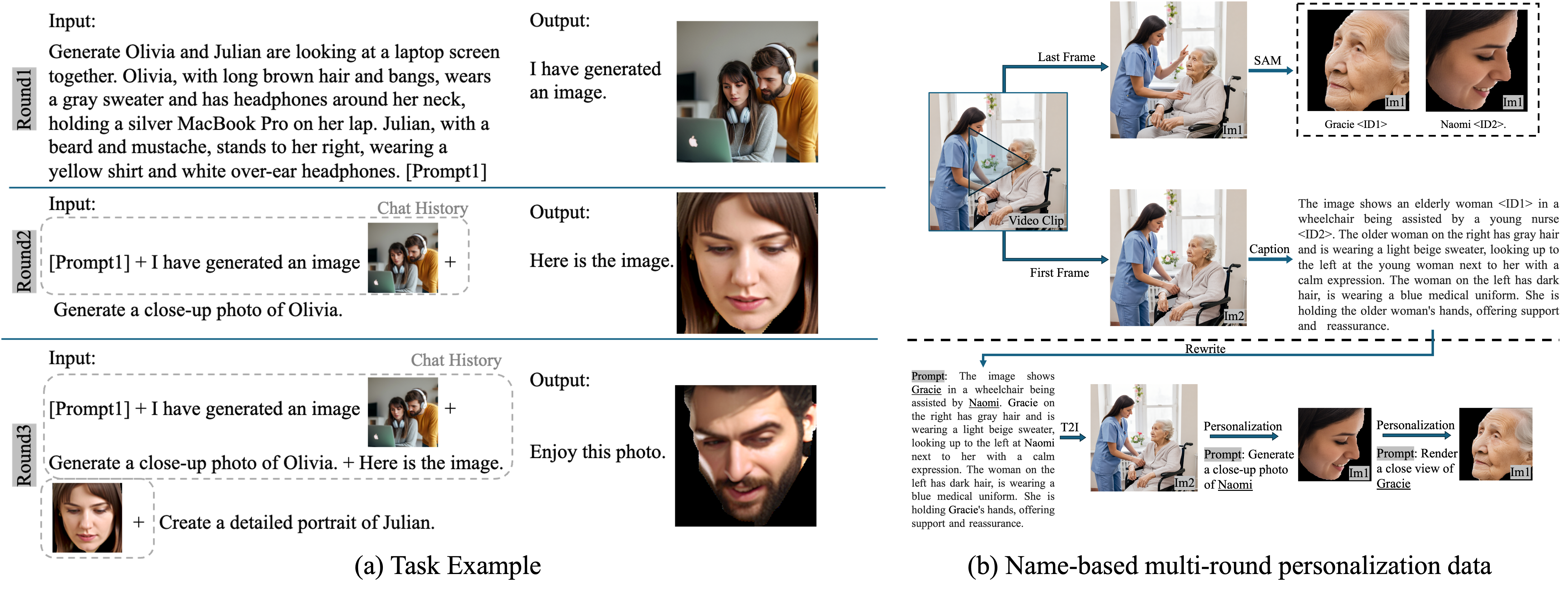
Our designed task begins with an initial text-to-image generation, followed by two rounds of personalization. In the first round, two individuals (e.g., Julian and Olivia) are generated from detailed descriptions and assigned names. In subsequent rounds, only names are referenced, requiring the model to retrieve and associate identity information and face from earlier text and image context. This intentionally challenging setup demands fine-grained, token-level (text tokens related to name and image tokens related to face) chat history reasoning rather than incremental image edits. The dataset is constructed from video clips featuring two individuals to support this design, as depicted in subfigure (b).

Experiments show that our model correctly generates both individuals in the first round and, more importantly, consistently produces the correct faces in later rounds based solely on chat history. These results highlight the potential of MLLMs for conversational, multi-round personalized image generation. Please find more comprehensive discussions in our paper.
Please also see our arXiv paper with non-Markov multi-round editting extention Here.
Paper | Slides | Poster | Video
Citation:
Coming soon